From Generalization to Inner Activations
By graham
One of the side effects of deep learning models becoming increasingly large is the amount of data that they intermediately generate which is then often ignored. Researchers have used this information to create explainability methods which show importance relative to a specific input it is connected with, but often the intermediate values are disregarded and mostly underutilized. Although this intermediate data can become increasingly unwieldily in size as the networks grow, the ability to monitor specific layers is a valuable tool that provides insight into how the model is learning as well as vague generalities about how the model performs overall (e.g. where are specific features begun to be extracted or where is noise filtered out).
These intermediate values follow every layer of the network and while they are related back to a specific input (and are well known for being superimposed back on something like the input or used to train a linear classifier like in TCAV) some researchers are taking a different approach and using sets of these inputs to understand the inner workings of deep learning models and make observations about a variety of topics related to the model. These observations include everything from how well does the model generalize to can these values be used to explain the class sensitivity at a layer.
This blog posts discusses a few different papers and the various methodologies they utilize as well as possible implications and future directions that I am pursuing in my research.
While all of the work mentioned has impressive empirical results, many of the most interesting aspects of the publications mentioned relate to how to better understand how deep learning models models “work” and questions about what information is being disregarded by not utilizing the intermediate values.
This post is broadly split up into two sections followed by a brief section of some preliminary results and guidance of what I see may be of possible research interest. The first section talks about the notion of generalization and how these intermediate values may allude to some greater understanding of how well a model is generalizing. The second section consists of papers that are adjacent to this and utilize these inner representations to show how one might capture information that allows a researcher to compare differing layers or networks in a way that is only dependent on the input data. While the connection may seem tenuous, the implications between the two are partly what is helping guide me on my current research focuses.
The full list of papers discussed are the following (although there is mention of other papers tangentially):
- Understanding deep learning requires rethinking generalization
- Accepted at ICLR 2017
- On the importance of single directions for generalization
- Accepted at ICLR 2018
- SVCCA: Singular Vector Canonical Correlation Analysis for Deep Learning Dynamics and Interpretability
- Accepted at NIPS 2017
- Insights on representational similarity in neural networks with canonical correlation
- Accepted at NIPS 2018
Generalization to Single Directions - ICLR Papers
The first paper of the ICLR publications, Understanding deep learning requires rethinking generalization, is quite highly regarded already and has other blog posts specifically about it (1, 2) so I will not dive into it too deeply but mainly use it as a starting point. The basis of the paper is that they are able to show that a network can memorize a random labeling of the data and can achieve no training error and at the time was broadly challenging and putting forth some conclusions about the generalization ability of deep learning models. There are a range of views about this paper and are easily viewed on pages such as the openreview of it, regardless the loose connection to the follow on topics that I mention and other papers is what makes it of interest for this post. Below we see an image of their results that show the convergence of train loss and test loss for various experiments they ran.
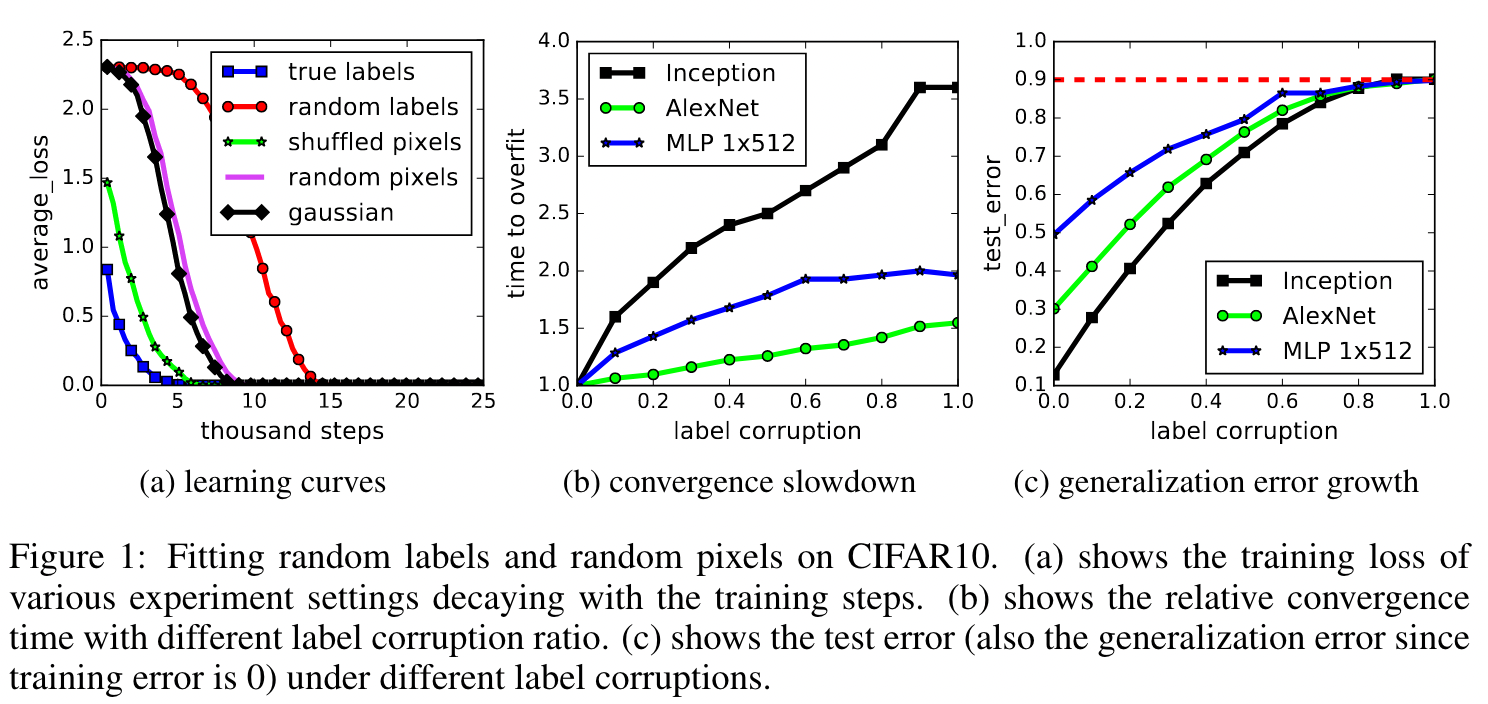
While the paper is worth a read on its own, the reason it is contextually interesting in this blog post is in connection with a paper the following year.
In 2018, a paper titled On the importance of single directions for generalization puts forth the idea of “single directions” which they define as “the activation of a single unit or feature map or some linear combination of units in response to some input”. This is very similar in many regards to the inner representations which come from layer outputs in relation to a specific or set of inputs and they investigate many aspects of these “single directions” with various methods including perturbations.
One of the findings of the paper is clearly stated on the first page: We find that networks which memorize the training set are substantially more dependent on single directions than those which do not, and that this difference is preserved even across sets of networks with identical topology trained on identical data, but with different generalization performance. This has direct overlap with the paper from the preceding year and has very interesting implications that while many will first consider how well a model generalizes based on some test set, understanding if a deep learning model generalizes may be pursued as well via some understanding of the activation space or intermediate values.
They further go on to discuss that a possible usage of these single directions is for estimating generalization ability of the model and go on to have some preliminary results that show this but say that further research is needed for more complicated datasets. This is a fascinating result from a practical and real-world use perspective where there may be necessary requirements to show in multiple ways that the model generalizes well or the inner workings are quantitatively monitor-able in some way.
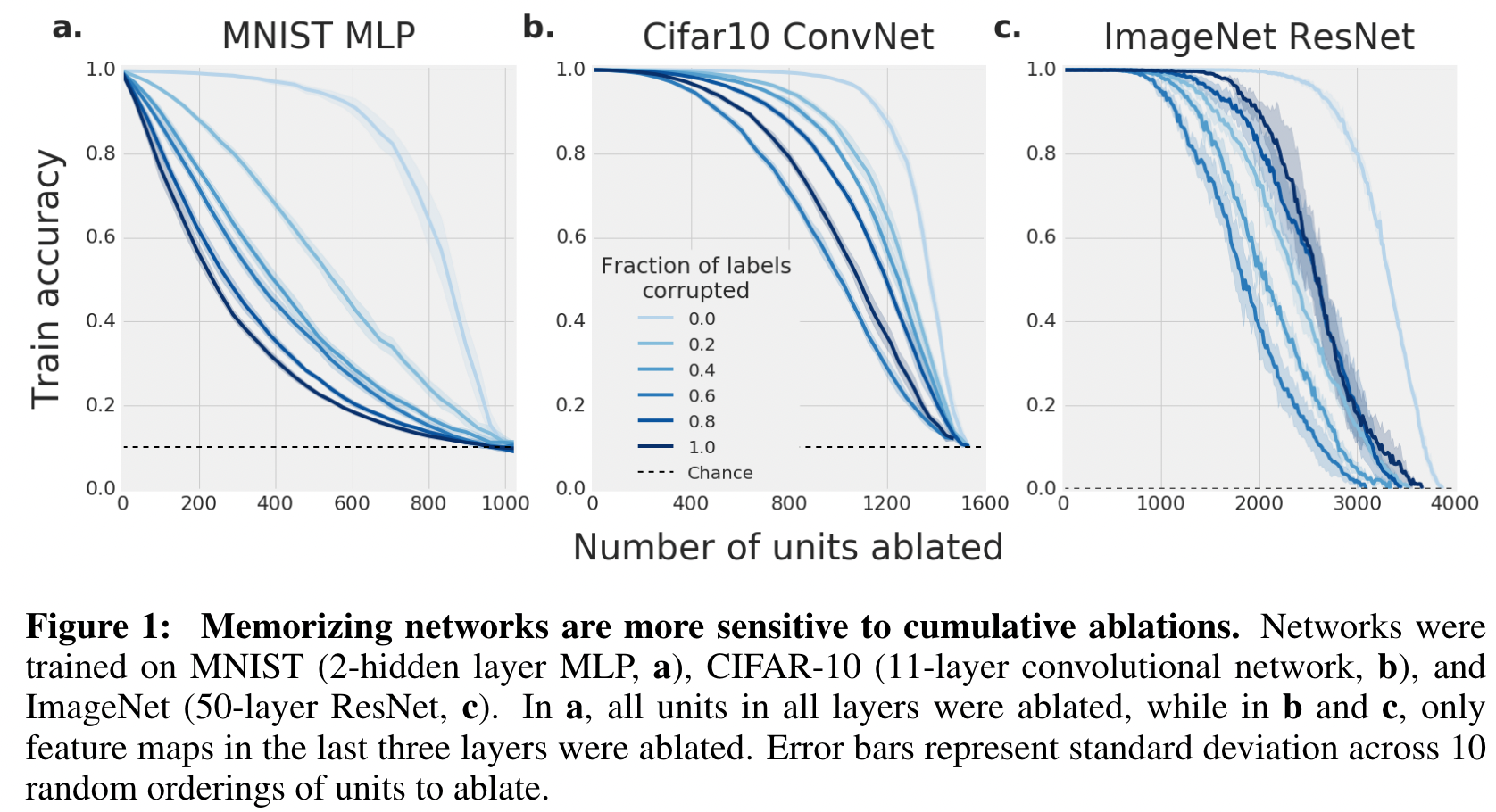
Inner Representations
While the above papers come from from ICLR conference publications, the next group of papers investigates a very unique idea about how we can compare two inner representations from differing layers and networks to get values that provide numerical understanding via coefficients and how these coefficients give a similarity metric. An example of this is shown below where a comparison is shown between layers of differing architectures as the method allows comparisons without natural alignment.
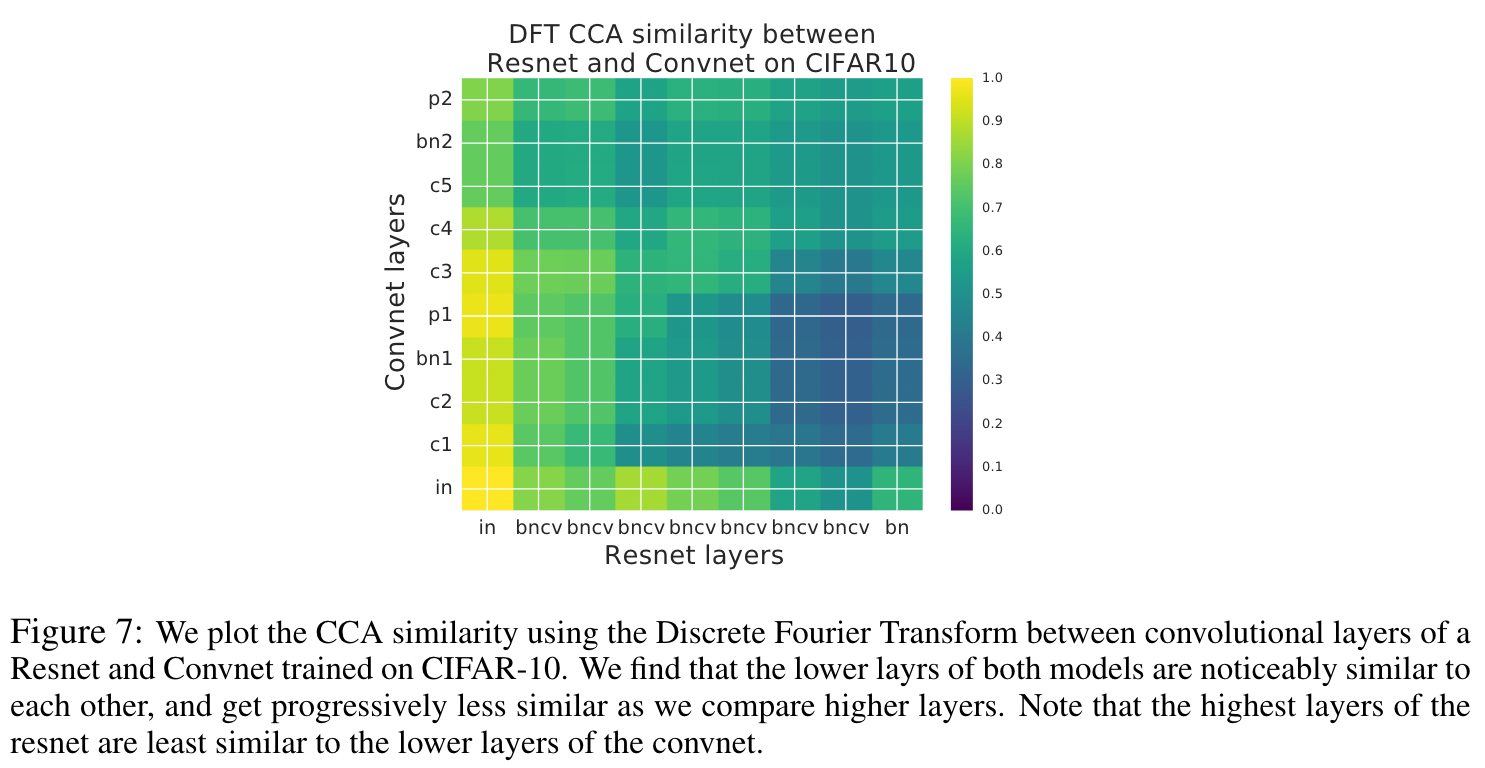
The authors of the paper, SVCCA: Singular Vector Canonical Correlation Analysis for Deep Learning Dynamics and Interpretability, put forth a pretty unique and interesting way to examine and compare what they call “representations” that allow for comparisons between different layers and networks (as shown in the image above). Generally when determining a way to compare the inner representation of differing networks it can be quite abstract and there is no clear one-to-one comparison from model to model. For similar network architectures, the most basic approach would be to compare based on layers and then compare the neurons of those layers, but this does not work as easily if there is no general alignment from a neuron in one network to a neuron in another network (which means most different architectures). The authors of this paper explain a methodology they call Singular Vector Canonical Correlation Analysis (SVCCA) which looks at two sets of neuron outputs from the same data input values and allows comparison between models which are not similar in a manner by comparing the subspaces of these inner representations. The method combines Canonical Correlation Analysis (CCA) with a Singular Value Decomposition (SVD) for these two different sets of outputs to give a correlation coefficient that is “aligned” in some subspace. To compare the values from the SVCCA they use baselines composed of random and maximum activation neurons.
While a bit of an oversimplification and ignoring some steps (the full methodology can be found here) a brief sketch of the methodology is as follows:
acts1 = ... # first group of activations
acts2 = ... # second group of activations
numx, numy = acts1.shape[0], acts2.shape[0]
covariance = np.cov(acts1, acts2)
sigmaxx, sigmaxy = covariance[:numx, :numx], covariance[:numx, numx:]
sigmayx, sigmayy = covariance[numx:, :numx], covariance[numx:, numx:]
# rescale covariance to make cca computation more stable
xmax, ymax = np.max(np.abs(sigmaxx)), np.max(np.abs(sigmayy))
sigmaxx /= xmax
sigmayy /= ymax
sigmaxy /= np.sqrt(xmax * ymax)
sigmayx /= np.sqrt(xmax * ymax)
... # intermediate scaling, checks and other slightly important steps
# from this we then get the coefficients
u, s, v = np.linalg.svd(np.dot(invsqrt_xx, np.dot(sigma_xy, invsqrt_yy)))
cca_coef1 = cca_coef2 = s
A follow up to this research was in part a publication titled Insights on representational similarity in neural networks with canonical correlation, which provides further insight into representational properties of deep learning models. One of the conclusions in this follow up paper relates to how the representations that come from CCA and SVD contain both “signal” and “noise” components. This is very elucidating from a standpoint of comparing networks (which they mention and show results as well related to work such as Linear Mode Connectivity and the Lottery Ticket Hypothesis that takes quite a different approach using model weights) that generalize versus memorize, which is exactly what is discussed in the first two papers of this post. Understanding how we might show these “signal” components both compared to other networks as well as throughout training and testing own would be very beneficial and possibly numerically measurable with some amount of further research. Along with this, it would be incredibly helpful in providing a novel approach to showing if a network is generalizing well for production use cases where a model may need to be tested and verified in multiple differing ways.
Related Results and Preliminary Findings
Connecting the dots from these differing research publications, there seems to be a wealth of information contained within these intermediate values. One of the difficulties with these values though is that they are obfuscated by complex network architectures and often being obtuse or difficult to deal with in that comparing the values from one model layer to another layer or differing model requires some amount of either mathematical justification or subjective explanation.
Before learning about and reading about some of these papers discussed above, we became interested in the idea of knowing how the inner workings of a deep learning model may have unintended side effects related to explainability and generalization. While it is easy to understand the definite mathematical functions that apply to an input to create an output, having a qualitative comprehension about what the layers progressively do allows for more nuanced direction about how to not only build perhaps more predictive models, but create ways to explain and verify models that have more likelihood of being used in the real world.
The following preliminary results come from experiments where following every training epoch, an image has gaussian noise added to it (with $ \mu=0 $ and $ \sigma=0.2,0.1,0.01 $). The images come from MNIST and while the gaussian noise is barely noticeable or even imperceptible to humans, the test and train accuracy are not drastically altered by this amount of noise. While we use multiple images as a starting point, each of these images is individually analyzed with a group of itself that has been perturbed and then the SVD is calculated from this group and analyzed together with other instances from its class.
The initial belief that we had was that by looking at the singular values and the associated explained variance of these singular values, a network that is learning to not only memorize would be capable of filtering out more of this gaussian noise after activation functions throughout the network.
What we expected to see for a network that is capable of filtering the noise out (while not being explicitly trained to do so) would be more variance captured by the first component the more epochs we train. Rather what we see in the image below of the explained variance of the first component is that it actually captures less of the variance and there is more noise being noticed during the convolutional layers although this becomes less so for the later layers in the network. The labels for the lines in the charts bellow are labeled by the layer they follow and the $ \sigma $ of the noise added (also noted if it is during a hold-out test set as well).
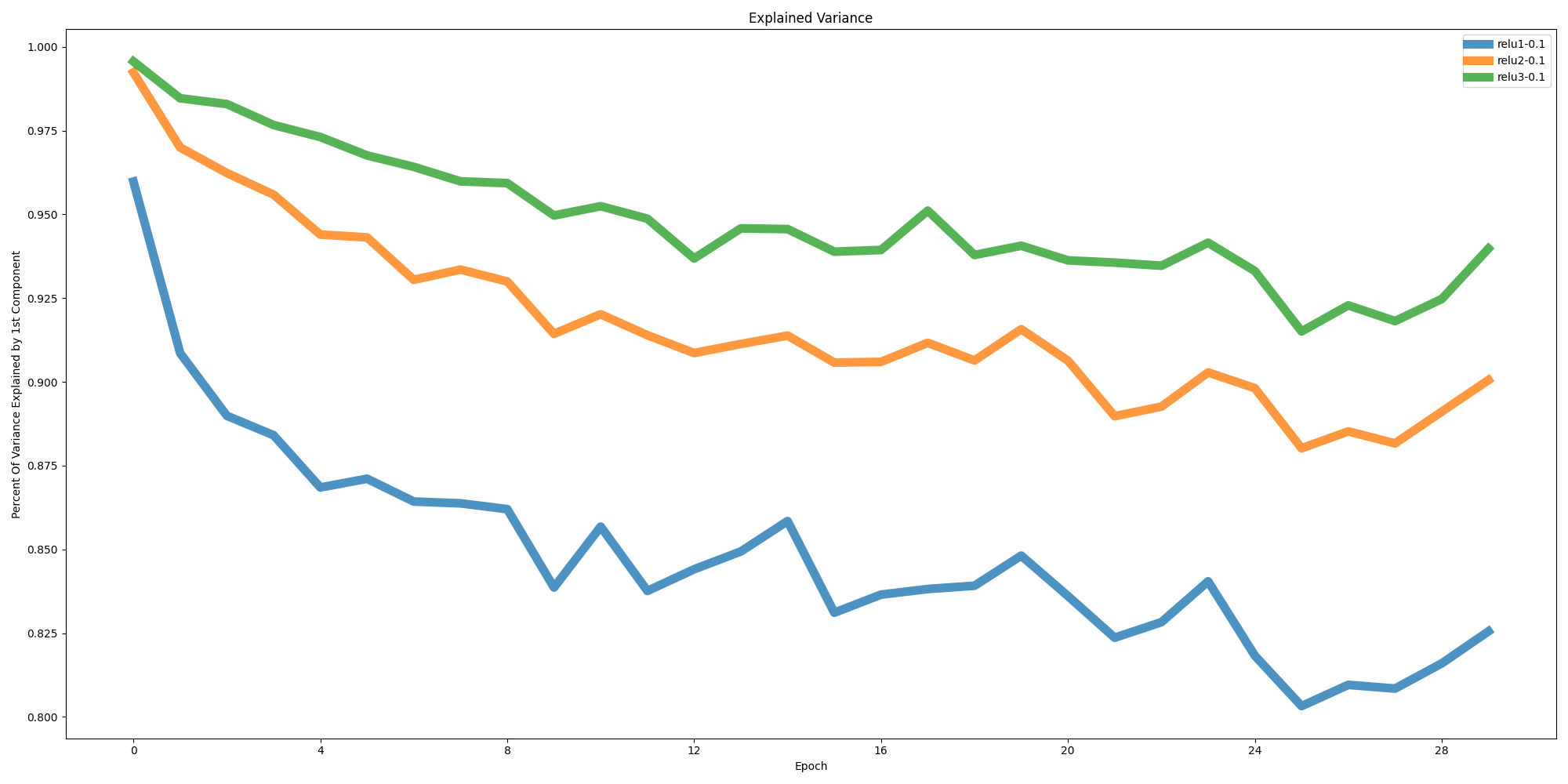
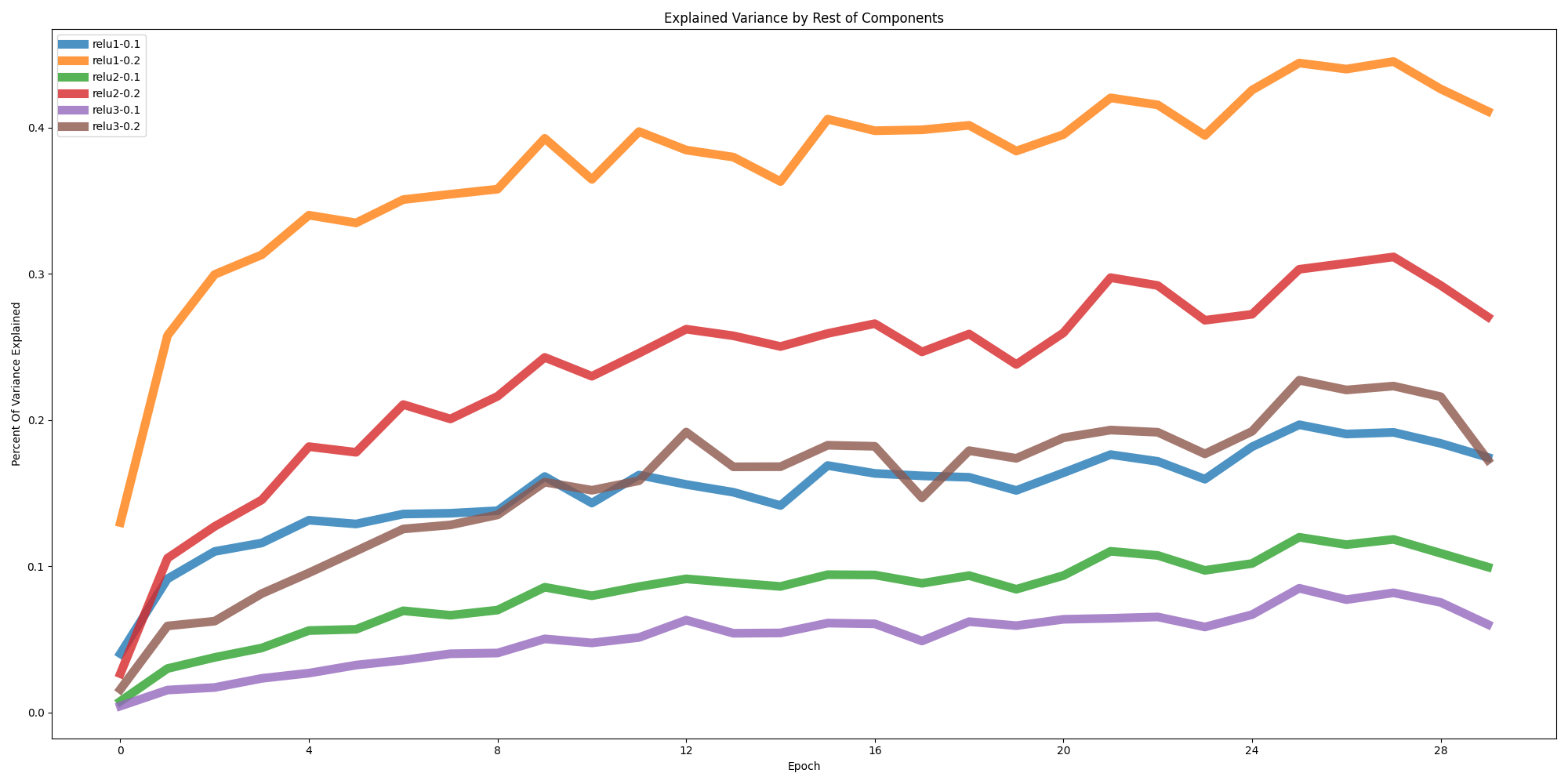
We see this even more so when examining the second component as well as the rest of the components and their associated explained variance as in the images below. The second components in general continue to capture more and more of the variance, this presumably means our basic convolutional network and the associated feature maps are more susceptible to noise than we would anticipate for a model that we believe would be generalizing. While we see these values somewhat plateau for the rest of the components around where the train and test loss converge (shown in the last image), we also find that this convergence is much more gradual for the later layers which could possibly mean that the model is learning to filter out more of this gaussian noise without being explicitly trained to do (and could have implications related to generalization as well as adversarial defenses). Regardless more rigorious experimentation and evidence is needed to justify these claims.
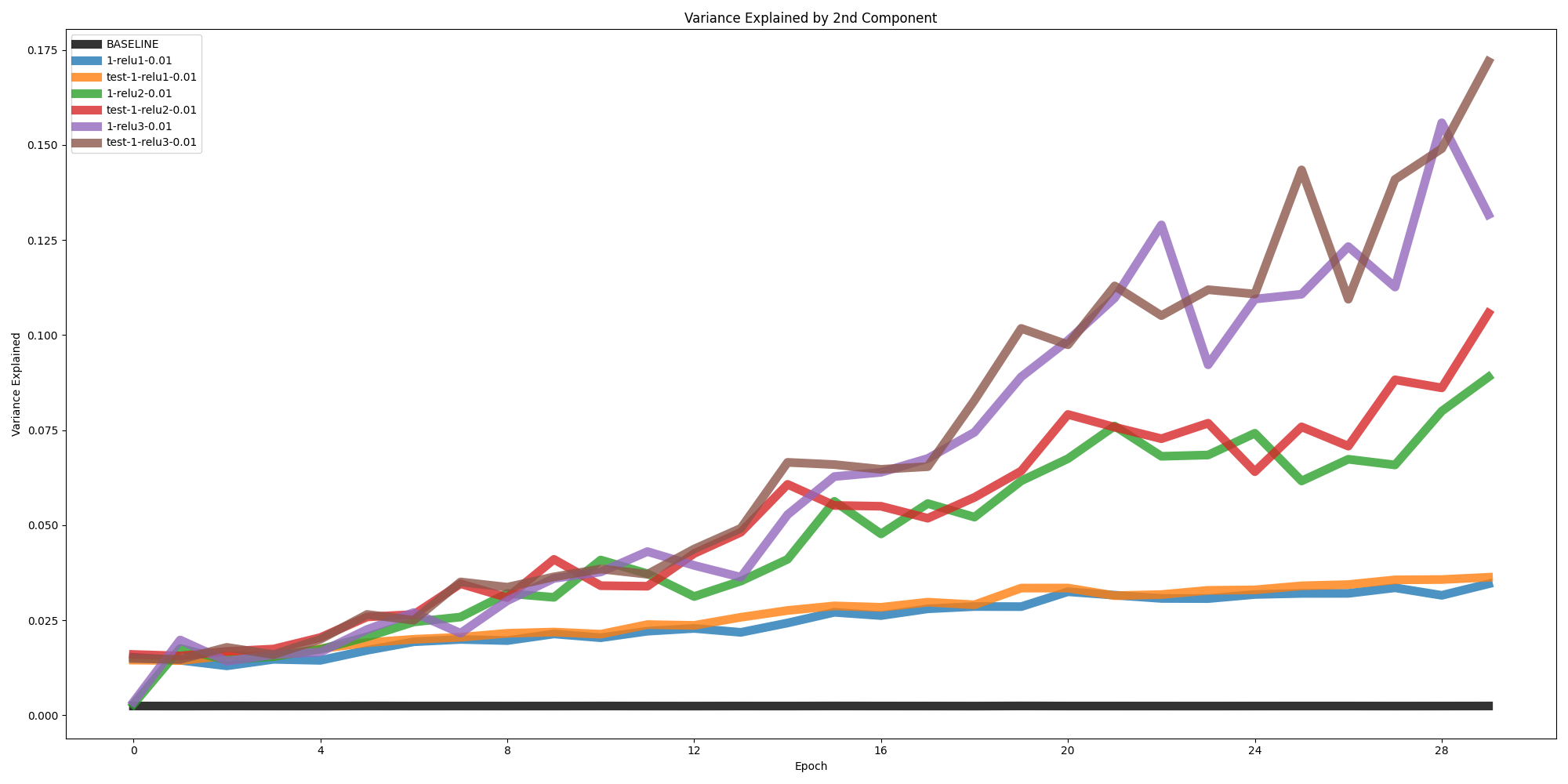
This last image is interesting in part due not to the magnitudes of the singular values, but rather their rate of change. If we were using a group of images that were not perturbed we would see all but the first singular values be 0 and this singular value would increase with magnitude as the trained weights amplify this signal with no noise. Rather what we see with a group of perturbed images is the first singular value dropping initially and more volatility in general for the initial epochs until it gradually begins to rise around where the train and test loss converge (train and test loss not to scale on SVD plot, superimposed only for clarity). You can take this to possibly mean that there is an almost gradual shift from the network changing from memorizing the input data to more gradually becoming a network that you would describe as generalizable. Rather than the network being one or the other, there is a spectrum between these two and possibly ways to track this during training and testing.
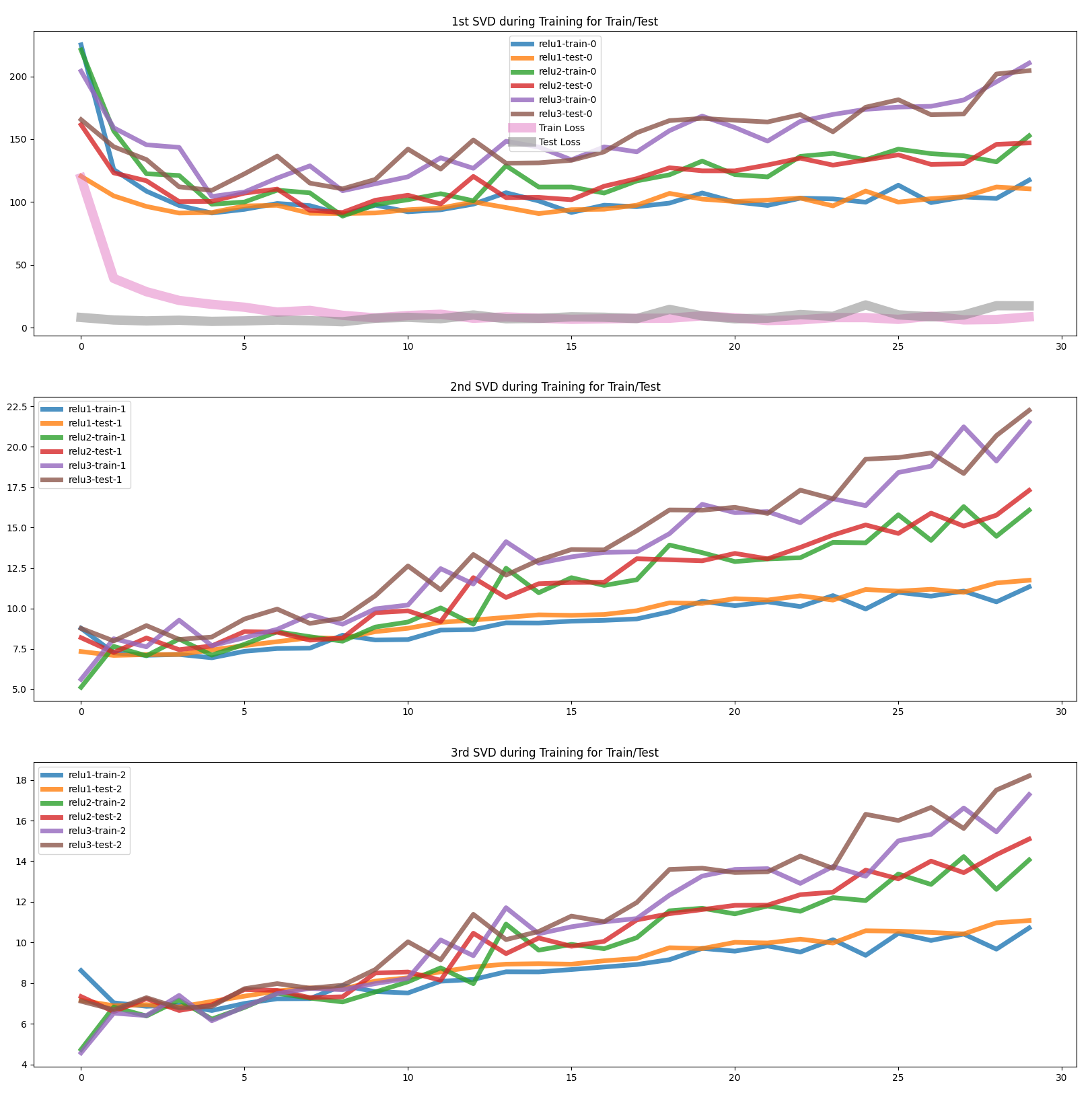
The hope with the experiments thus far is to understand something about generalization and ability of the network to filter out something such as noise without being explicitly trained. Thinking of how many adversarial attacks that once they are known of, they can be more easily trained against but can bypass human with ease (for instance the CW2 Attack), we see a potential research avenue whereby monitoring the internal activations with approaches from traditional linear algebra as perhaps a way to tangentially monitor a network in the same way the single directions from one of the previous papers mentioned. Further research is indeed needed with the intent to show some form of monitoring of a model or a layer with a perturbed input (and adversarial attacks) and how even though the input may be minimally perturbed, we can understand whether the models inner representations are noticeably different than expected for a model that generalizes well.