5 Thoughts On Agent Engineering
While Agents became the buzzword of 2024, their real-world usage thus far has fallen short. The idea of agentic systems is likely to further embed itself into software engineering discourse despite most developers still having an ambiguous understanding of both what an agent is and the ambiguity of how to design and engineer for this new paradigm.
It’s not hard to imagine this paradigm becoming as practical and commonplace as the usage of web-browsers for office work but the journey to that arrival is far from clear-cut as there are still many challenges about how these agents should be designed in a manner that allows them to be easily reused, adapted, deployed and monitored.
My read is that the utility of these tools is sharply bifurcated right now. It is hard to find engineers who do not lean on AI assistance in some capacity, while I’ve seen plenty of senior and staff level engineers state plainly they do not find it helpful or see reason (yet) to adapt their workflow to incorporate AI. At this point, choosing not to use these tools is probably putting yourself at a real disadvantage. Here are some of my initial thoughts on the topic:
1. Design Patterns Will Diverge From CRUD Apps
Arguably the most capable application of LLMs for designing and implementing end-to-end software systems has been when utilized for the development of create-read-update-delete web applications. This is largely beneficial as it allows devs to spin up complex web apps in a fraction of the time that it would have taken before. Unfortunately, the design patterns that LLMs tend to prefer (and are extremely common for CRUD apps) are often at odds with building agentic systems. At present, this mostly results in initial agents that utilize brittle patterns and design choices and result in systems more akin to a Workflow than open-ended agents.
2. Data Structures Become Footguns
Competency in modern programming is underpinned by understanding the data flow and the underlying data structures of complex programs. This notion is not going away for agent systems, but utilizing these data structures from models will likely result in brittle systems and additional complexity that ends up being model-specific. Most likely, this means requiring additional tests and checks for transforming text to and from data structures and can cause hurdles about updating models or being model provider agnostic. For a minimal example of this, using pydantic-ai, here is a straightforward case where marshalling the model’s output into a data structure will fail:
from typing import Annotated
from pydantic import Field
from pydantic_ai import Agent
from pydantic_ai.models.openai import OpenAIModel
from pydantic_ai.providers.openai import OpenAIProvider
from typing_extensions import NotRequired, TypedDict
class Whale(TypedDict):
name: str
length: Annotated[float, Field(description="Average length of an adult whale in meters.")]
weight: NotRequired[
Annotated[
float,
Field(description="Average weight of an adult whale in kilograms.", ge=50),
]
]
description: NotRequired[Annotated[str, Field(description="Short Description")]]
agent = Agent(OpenAIModel("qwq", provider=OpenAIProvider(base_url="http://localhost:11434/v1")), result_type=list[Whale])
result = await agent.run("Generate me details of 3 species of Whale.")
print(result.data)
Regardless of what model is being used (or all the self-hosted and most of the external models I tested), it’s common to run into issues:
pydantic_core._pydantic_core.ValidationError: 3 validation errors for typed-dict
response.0
Input should be an object [type=dict_type, input_value='1. Blue Whale (Balaenopt...angered due to whaling.', input_type=str]
For further information visit https://errors.pydantic.dev/2.10/v/dict_type
response.1
Input should be an object [type=dict_type, input_value='2. Humpback Whale (Megap...le conservation status.', input_type=str]
For further information visit https://errors.pydantic.dev/2.10/v/dict_type
response.2
Input should be an object [type=dict_type, input_value='3. Sperm Whale (Physeter...ales are more solitary.', input_type=str]
For further information visit https://errors.pydantic.dev/2.10/v/dict_type
The above exception was the direct cause of the following exception:
(...continues with additional errors...)
In the case where we forgo the data structure and solely ask the model to output text, the model is quite capable:
agent = Agent(OpenAIModel("qwq", provider=OpenAIProvider(base_url="http://localhost:11434/v1")))
result = await agent.run("Generate me details of 3 species of Whale.")
print(result.data)
**Species 1: Humpback Whale**
* Scientific Name: Megaptera novaeangliae
* Habitat: Warm and temperate waters around the world, including oceans and seas in all major continents.
...(continues and provides additional details and additional species)
It is easy to disregard the trade-offs that will come from dealing with the complexity of models outputting data structures (or just anticipate the next models being more capable) but it also can mean that the best design decision is to forgo data structures unless absolutely necessary when utilizing models for agentic systems. When designing systems where models are primarily using text as the data structure, many of the standard ideas of how to use data structures that are commonplace in software development will need to be reconfigured.
3. Thinking Models Are The Greatest Leverage Point For Open Ended Tasks
I am relatively surprised at how well the latest open source thinking models work when integrated into agentic systems. Rather than having to explicitly define workflows and directed graphs that the agent can act upon, thinking models allow you to offload large amounts of these design decisions to the prompt and agent tools itself and allow the model to direct its own workflow. I’ve found this particularly true for a deep research implementation where allowing the model to direct its own research direction results in the model arriving at vastly more intricate research directions than trying to explicitly define this process. There are a number of open source takes on this as well, e.g. open-deep-research, gpt-researcher, and another, though I leaned on my own implementation here.
4. The Low Hanging Fruit Are Not Workflows
The AI obsessed seem to envision agents replacing the majority of tasks office workers do through a mouse and keyboard. This assumption presumes these tasks are akin to straightforward workflows that tools such as LangChain seem highly suited for but the reality is that most tasks which can be automated into a workflow have a better interface to do these through or have barriers to doing these via code. Rather, the low-hanging fruit that AI agents will be able to be developed for and have measurable impact will require more open-ended approaches that allow the system to generate and iterate on its own approach.
5. Agents Will Drive Local Model Usage
Right now, the overwhelming majority of AI usage is via hosted models. Once AI has become more saturated and become embedded into most software, there will become increasing interest to offload parts of these systems to the client. Right now this is almost non-existent despite already being possible. For instance with recent versions of Chrome, pull up the javascript console and run the following:
session = await ai.languageModel.create({systemPrompt: "Generate a JSON that contains a question and answer based on the following post"})
output = await session.prompt(document.documentElement.innerText)
console.log(output)
Which can give you the following result:
{
"question": "What are the key challenges and potential solutions associated with designing agents?",
"answer": "Designing agents presents several challenges. One is the need for more sophisticated data structures beyond simple key-value pairs, as LLMs excel at working directly with text. Another challenge is the lack of clear guidelines for designing and deploying these agents, especially in complex scenarios where open-ended tasks are required. However, thinking models offer a potential solution by allowing agents to generate and iterate on their own workflows, potentially automating tasks that are difficult to define as traditional workflows. The increasing availability of local AI models and the desire to reduce reliance on external APIs could also contribute to the development of agents."
}
While tools like MCP are allowing agents to have more breadth from applications, agents which utilize a browser have been mostly limited to using frameworks such as Playwright. To more closely integrate these systems together, various forms of local models (e.g. run from the browser) may be a primitive that enable agentic systems to become integrated into day-to-day office work. Or, as the pervasiveness of AI slop becomes unbearable, these local models will intermediate experiences such as browsing the web without requiring vast amounts of personal data to be sent to external services. Usages such as cleaning up web browsing experience may not seem like agentic systems but the underlying engineering that builds these amalgamations is likely to be much more probabilistic than the traditional software engineering approaches that most engineers become familiar with.
Where This Leaves Engineering
A thread running through all of these is a question I keep coming back to: will the tradeoff from AI/LLM add more complexity than it handles? For anyone who has not become fully “AI-pilled”, that is a hard thing to justify, and I do not think it is an unreasonable position to take. Building on top of these models brings a different kind of complexity than traditional software. It is less about raw opacity and more that the core behavior is non-deterministic and hard to step through or reproduce, which means a lot of ingrained software design heuristics may need to be rethought. Adding complexity is not without cost, and while previously that cost often showed up as costly refactors and maintenance you could see coming, the complexity these models introduce is probabilistic and resists the usual ways of pinning a system down.
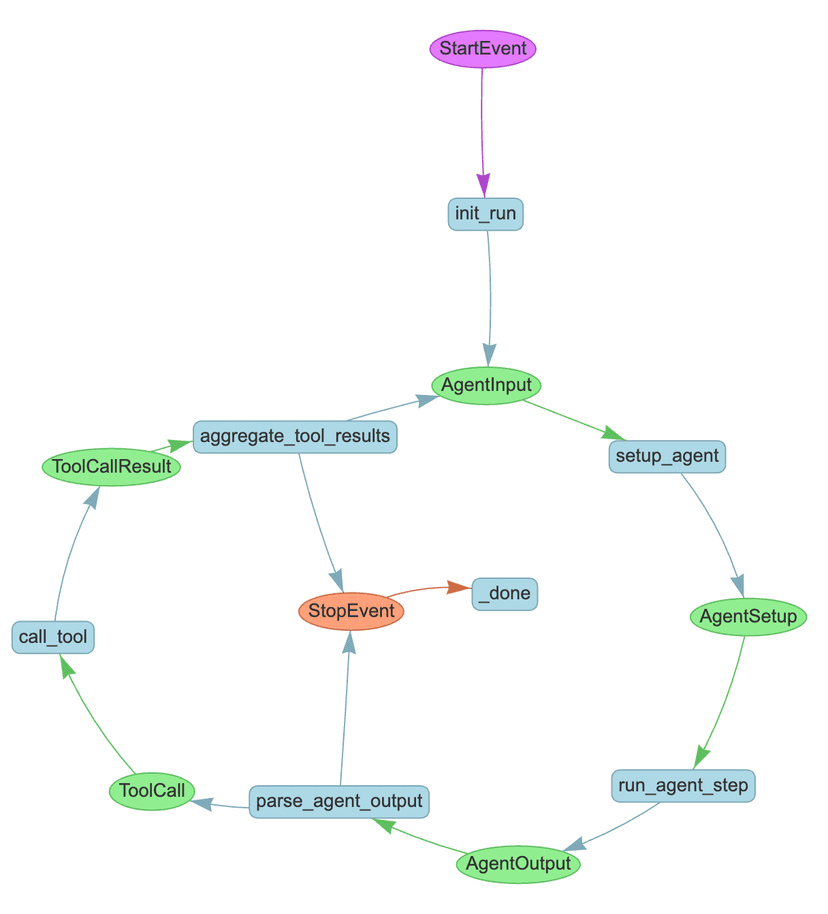
The graph below is a single agent loop drawn out as an explicit workflow. None of the pieces are complicated on their own, but it is a decent reminder of how much machinery sits behind “just run an agent,” and how much of the design ends up being about routing events and deciding when to stop rather than the logic inside any one step.
Conclusion
I am very interested in building or working on any ML/agentic software, if this is something you are working on or would like to integrate at your company, please reach out to me at graham.annett@gmail.com. Additionally, if you have any feedback at all please reach out to me.